
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 오블완
- Java
- 스프링시큐리티
- 엘라스틱서치
- 헥사고날아키텍처
- 오버로딩
- XSS
- kafka배포
- QA
- STOMP
- n8n
- 하이브리드접근법
- 프로토콜역할
- 테스트케이스
- 자바
- selenium
- 프로세스와스레드의차이
- 티스토리챌린지
- 자동화워크플로우
- 한화시스템부트캠프
- nplus1
- Kafka
- 메소드
- JPA
- N+1문제
- springboot
- jwt토큰
- 부트캠프
- 캐시의 작동 원리
- 자료구조
- Today
- Total
아쿠의 개발 일지
한화 시스템 부트 캠프 21주차 회고 본문

안녕하세요 시간이 빠른 건지 아니면 누군가 시간을 조종하고 있는 건지 벌써부터 헷갈리기 시작합니다...
이번 21주차는 추석이 껴 있는 날이어서 그런가... 교육을 들으러 목,금만 나갔습니다.
정말 변명은 아니지만 그래서 2일치 밖에 쓸 게 없어요...!
요즘 최종 프로젝트 기간이라 그런가... 매일 매일이 프로젝트 시간인데 이번 목,금은 스프린트를 위한 수업을 나가셨습니다.
사실은 프로젝트 들어왔을 때 이제 강의가 마지막인가? 하고 괜히 강가에 내버려진 어린 아이처럼 불안한 마음이 있었는데요..!
수업이 아직 남았다는 강사님의 말씀을 듣고 조금은 ! 마음의 평화를 얻은 것 같았습니다 하핫..ㅎㅎ
무엇을 배웠냐 ,,, ES, 스프링 배치, Redis 에 대해서 배웠습니다. 제가 이해 한 만큼 최대한 열심히 적어볼테니
` 이게 뭔 말이야 ,,, ` 하는 마음은 조금만 넣어주세요. 초심자의 마음(?) 으로 적었습니다.
일단 무엇을 배우기 전엔 배우는 것의 정의를 먼저 알고, 무엇을 배우는지 알고 시작하는 것이 좋습니다. (아마)
1. Elastic Search란?
루씬 기반의 검색 엔진이자, 분산 저장소입니다.
엘라스틱서치도 DB이긴 한데, RDB가 아니라 Nosql DB라고 보면 된다.
ES는 데이터를 json으로 저장한다. ES는 기본적으로 http 프로토콜로 접근이 가능한 REST API를 통해 데이터 조작을 지원한다.
그럼 왜 RDB보다 조회가 빠른가?
역색인이기 때문이다.
역색인은 일반적인 DB에서는 볼 수 없는 개념이기에, 간단하게 설명 하자면
일반적인 색인의 목적은 문서의 위치에 대한 index를 만들어서 그 문서에 접근하고자 하는 것인데 역색인은 반대로
문서 내의 문자와 같은 내용문의 맵핑 정보를 색인하는 것이다.
역색인은 검색 엔진과 같은 문서 내용의 내용의 검색이 필요한 형태에서 전문 검색의 형태로 주로 쓰인다.
DB에서 `hello` 라는 문구가 포함된 문자열을 찾으려고 한다면 SQL에서는 %hello% 라고 정확히 입력해야 검색이 가능하다.
하지만 ES의 역색인을 사용하면, 대소문자 구분 없이 어떤 문구가 와도 찾을 수 있다.

테스트를 해 보기 위해 일단 인덱스를 먼저 생성 할 것이다.
테스트는 `Postman` 으로 진행했다.
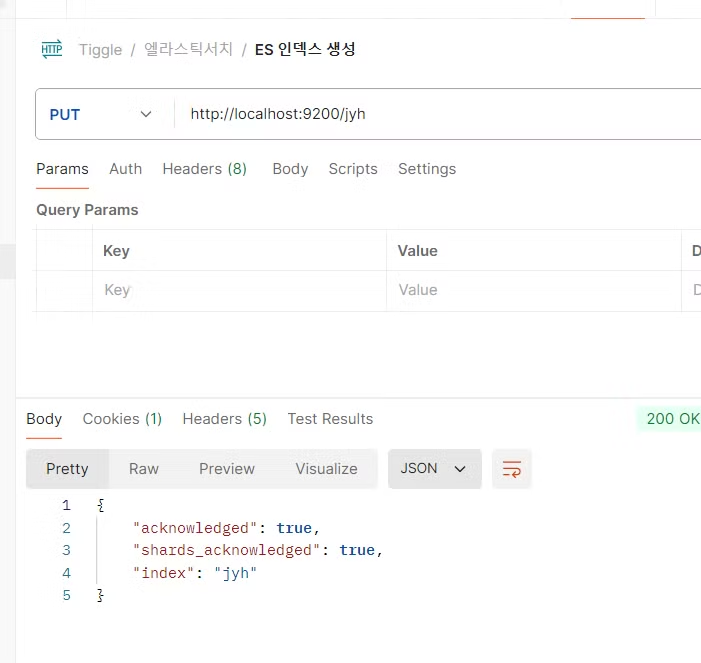
이렇게 하고 인덱스를 조회하면, yellow가 뜬다.
왜 뜨냐? 사본 데이터를 다른 서버에 1개 저장할 때 저장이 잘 안 돼서 뜨는 것이다. 그래서 설정을 조회 해서 변경을 해 주면 green이 뜨게 된다. 변경하기 전에 설정을 조회해서 뭘 변경 해야하는지 확인하고,
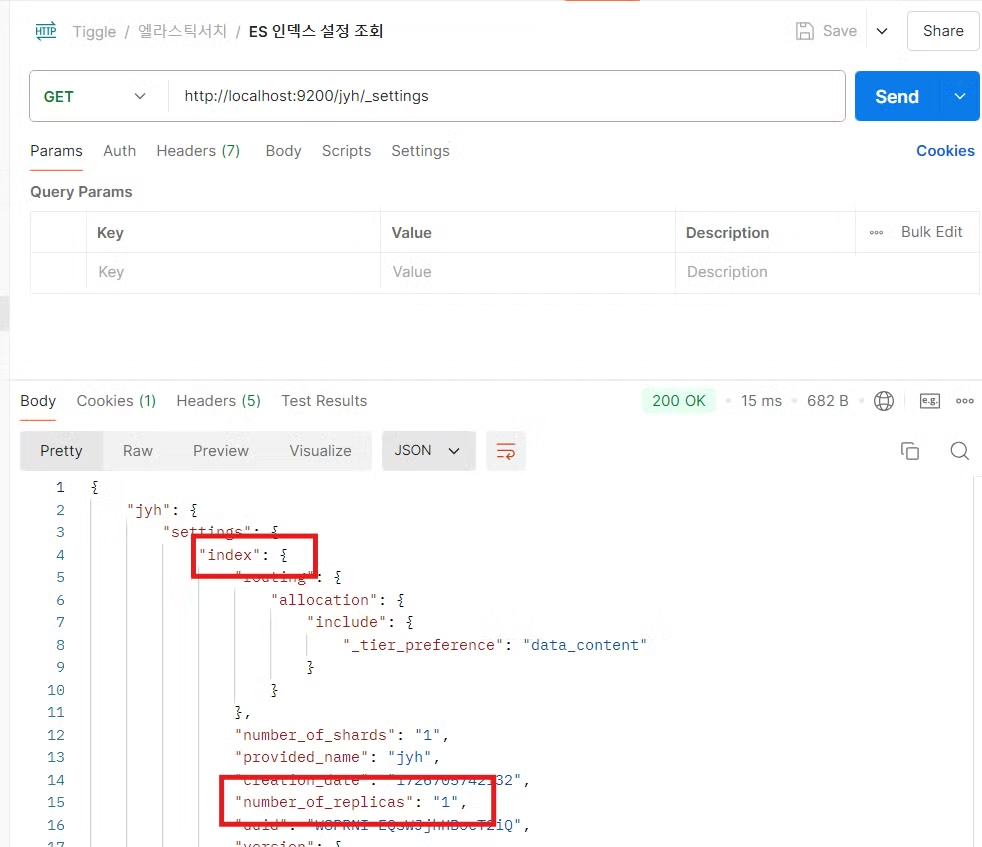
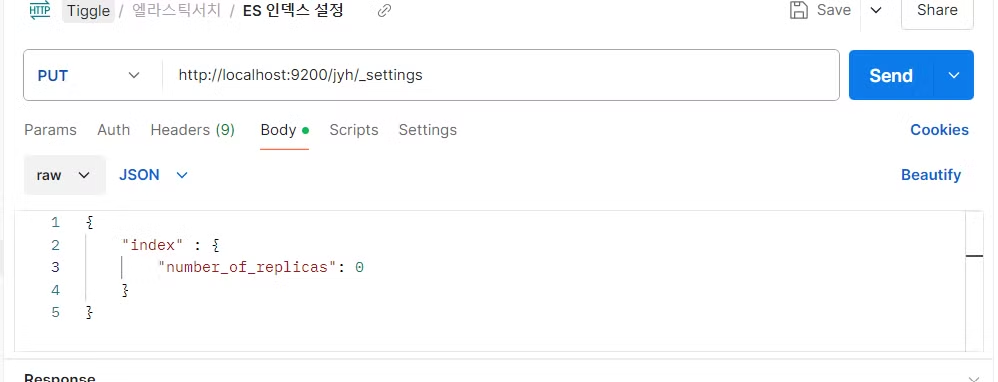
이렇게 변경 해 주면 green이 뜨게 되며 문제가 해결된다.
다음은 데이터 추가를 해 볼 것이다.
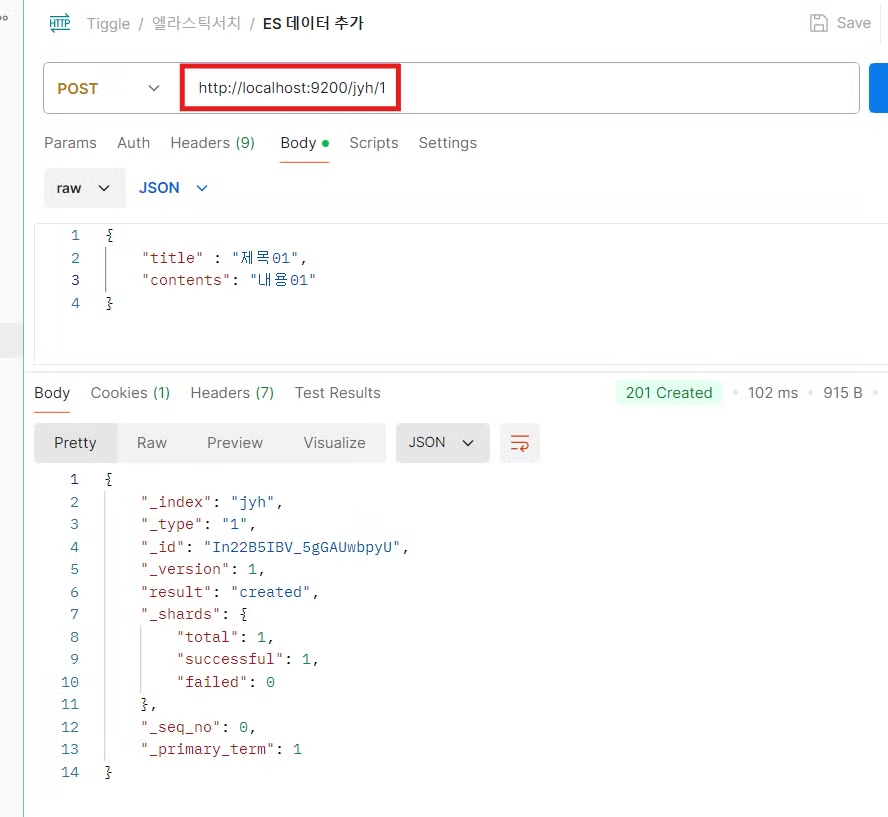
인덱스 이름을 써 주고, 옆에 숫자는 1번 데이터 라는 뜻이다. 이제 내용을 적어주면 다음 과 같이 변경 되었다고 뜬다.
ES 서버 상태로는 green , yellow, red 이렇게 3가지 경우가 있는데
- green : 정상
- yellow : 해결해줘야 하는 문제가 있는 경우, 원본 데이터 1개를 저장하고 사본 데이터를 다른 서버에 1개 저장할 때 사본이 제대로 저장이 안 된 경우
- red : 완전 맛이 간 경우
Postman으로 서버가 켜졌는지 확인을 할 수 있다.
http://localhost:9200/_cluster/health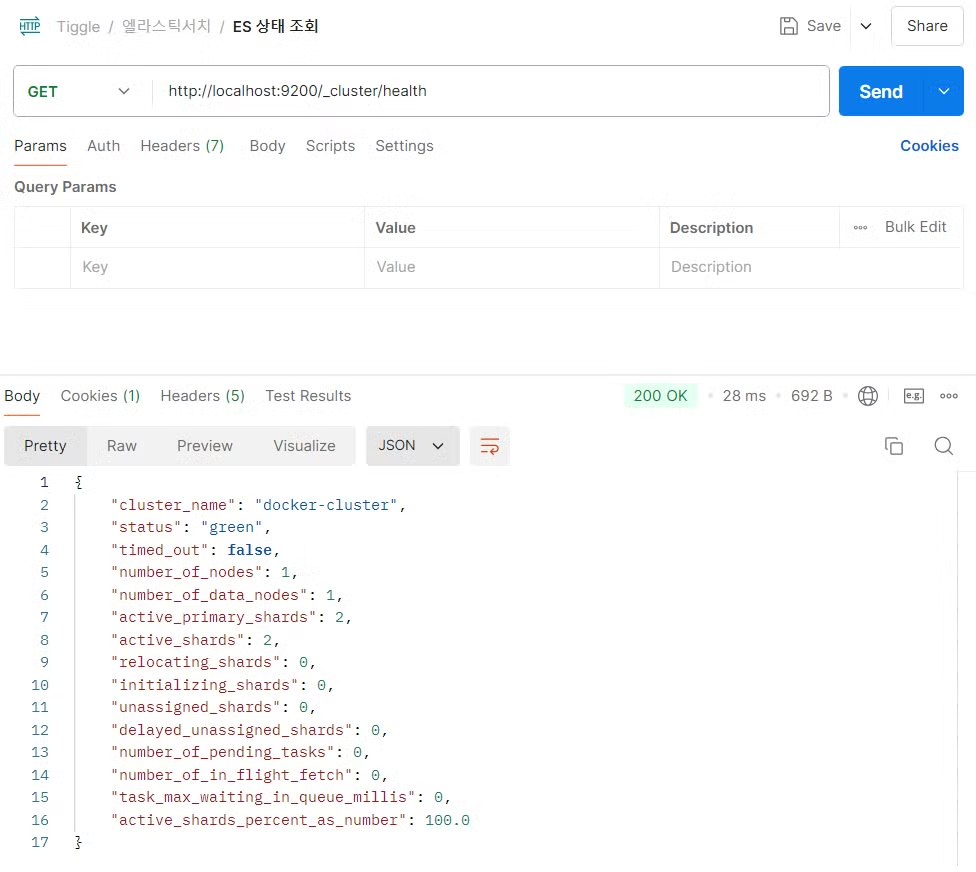
설정을 조회하는 방법인데, pretty를 붙이면 예쁘게? 내뱉어준다.
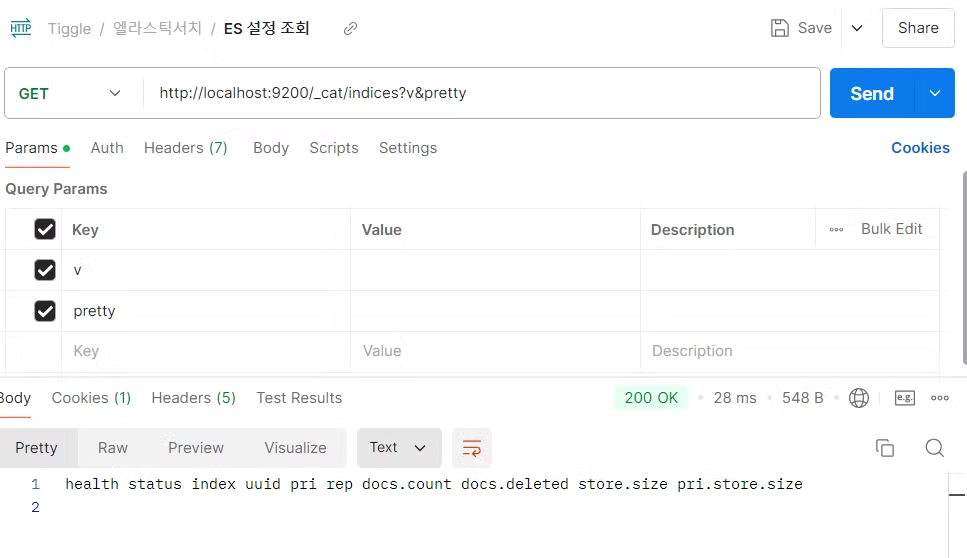
2. ES를 관리하는 방법
보통 키바나를 설치해서 엘라스틱서치를 관리한다.
키바나는 엘라스틱서치를 관리하기 위해 대시보드를 제공해주는 서버인데, 도커 컨테이너 안에서 키바나 주소로 접속해야 한다.
엘라스틱 서치랑 키바나랑 같이 설치하기 위해,
version: '3.8'
services:
elasticsearch:
image: elasticsearch:7.17.24
container_name: elasticsearch
environment:
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
kibana:
image: kibana:7.17.24
container_name: kibana
ports:
- "5601:5601"docker-compose를 작성해서 터미널을 열어주고,
docker-compose up -d를 해주면 같이 열리게 된다. 따로 따로 했다가,, 동시에 열어줘야 함을 인지하고 docker-compose를 부랴부랴 작성했다.
를 가면 대시 보드가 뜨게 되고, 모니터링을 하러 가면 된다..!
엘라스틱 서치 대시보드를 가서, exes -> bash를 치고
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.17.24-linux-x86_64.tar.gz
tar xzvf metricbeat-7.17.24-linux-x86_64.tar.gz위 명령어를 실행한다. 압축 파일을 푸는 명령어다.
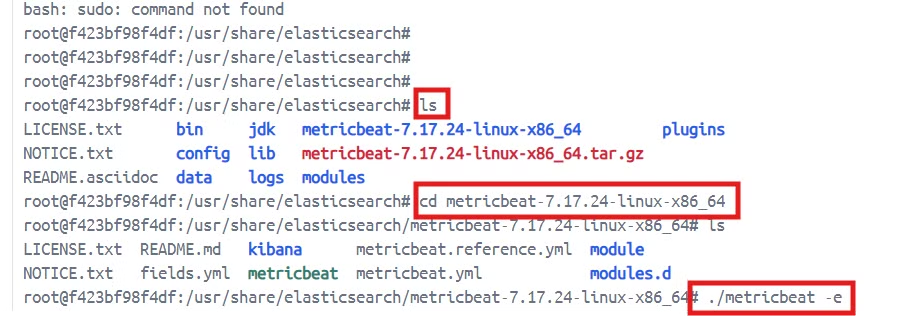
이제 실행하면 된다.

짜잔. 이렇게 화면이 뜨게 되고, 원래는 cpu 메모리랑 사용량이 나오는데 ! 삽질을 더 해봐야 할 것 같다!
스프링 배치
Spring Batch는 일괄처리라는 뜻을 가지고 있어 일련의 작업을 정해진 로직으로 수행하는 application입니다. 엔터프라이즈 시스템의 운영에 있어 대용량 일괄처리의 편의를 위해 설계된 가볍고 포괄적인 배치 프레임워크입니다.
배치 작업 서버는 원래 쌩 java로 되어 있었습니다.
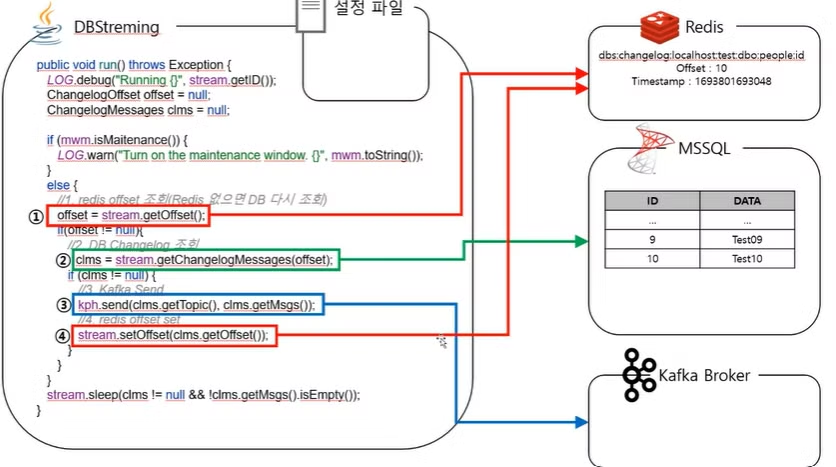
offset 이라는 값을 Redis에서 조회하고, Redis에서 조회가 된게 있으면 DB 이후의 추가된 값을 DB에서 조회하고, 이걸 Kafka로 보내는 ? 것이다.
이 방식을 이제 스프링 배치로 변경 시키는 건데,
원래 스프링 부트 2.7에서 배치 4.3을 썼는데, 필자는 스프링 부트 3.3이라서 배치는 5.2.1 버전을 써야 한다. 이때 문법이 많이 바뀌었다. 예전 문법과 많이 달라서 당황스러웠다...
스프링 배치 깃허브에 가면 예제 코드가 있다. 이걸 가지고 테스트를 해 볼 것이다.

어떻게 데이터를 바꿔줄지 생각을 해 본다. 예를 들면 쿠폰 지급이라던지, 등급 변경, 정산 등등 한 번에 처리가 필요한 요소들을 생각 해 본다.
처리하는 방법
Reader로 데이터를 읽어서 Processor에 전달하고, Processor가 Writer한테 전달해서 저장을 시킨다.
배치를 실행 시키면 작업이 다 끝나, 프로그램이 종료 되어야 성공적으로 수행 됐다고 볼 수 있다.
itemReader 종류가 엄청 많다. 공식 홈페이지를 참고하길 바란다...
실습
테스트를 하기에 앞서, yml파일을 먼저 작성 해줘야 하는데
server:
port: 9090
spring:
batch:
job:
name: vipJob
datasource:
url: jdbc:mariadb://192.0.50.3:3306/web
username: root
password: qwer1234
driver-class-name: org.mariadb.jdbc.Driver
jpa:
database-platform: org.hibernate.dialect.MariaDBDialect
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
logging:
level:
org.hibernate.SQL: debug
org.hibernate.orm.jdbc.bind: trace
이렇게 DB랑만 연결 해 주면 된다. DB는 mariadb를 도커로 열었따.
여기에서 batch 아래에 있는 것은 스프링 배치에서 실행할 작업의 이름을 지정하는 것이다. vipJob 라는 이름은 배치 작업을 식별할 수 있는 것이다.
배치 작업을 하기 전에 web 데이터베이스에 테이블들을 추가 해 줘야 하는데 그에 대한 정보는 여기 안에 있다.
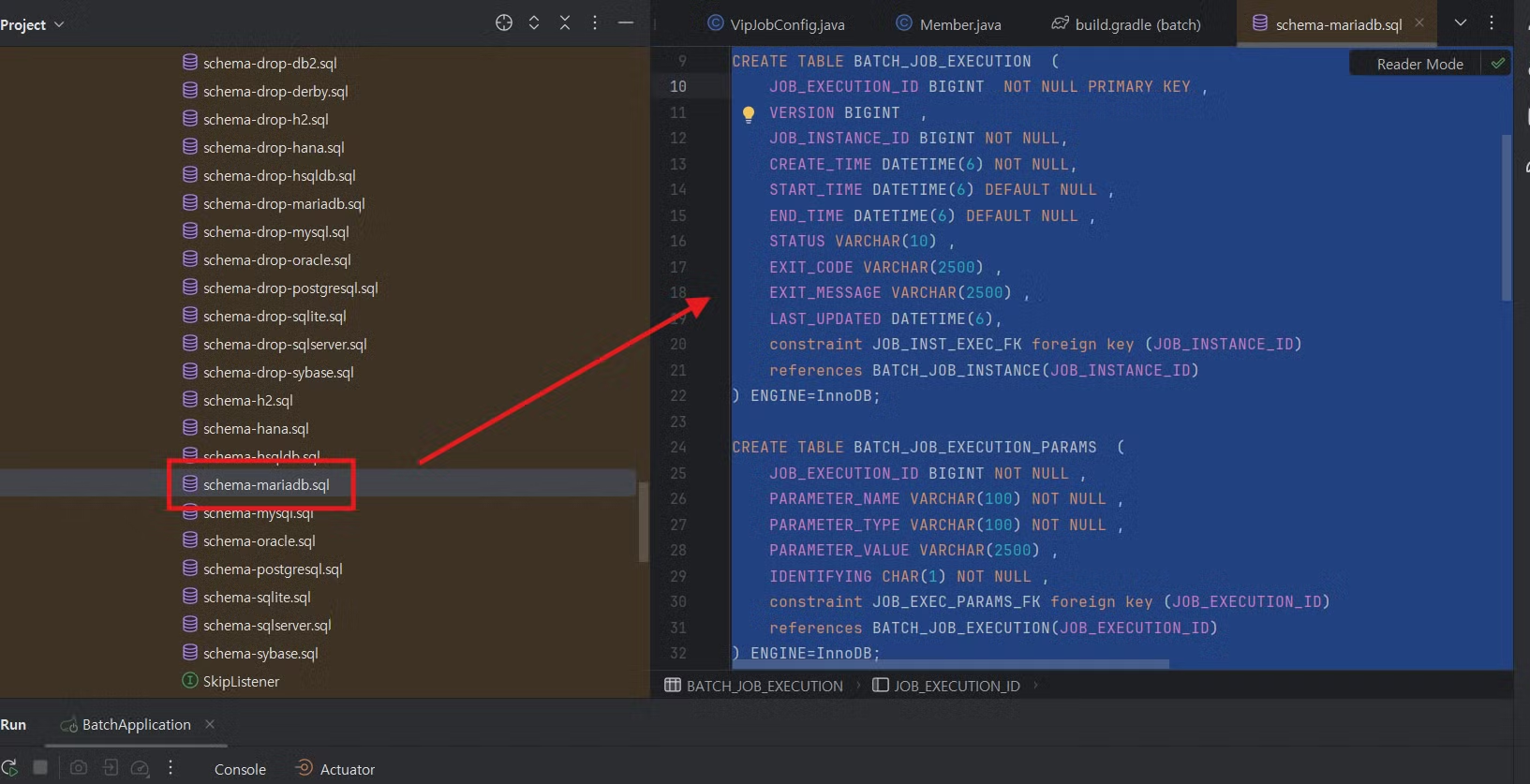
이 위의 값을 전부 복사하고, workbench로 도커로 실행 시킨 mariadb로 접속한다.
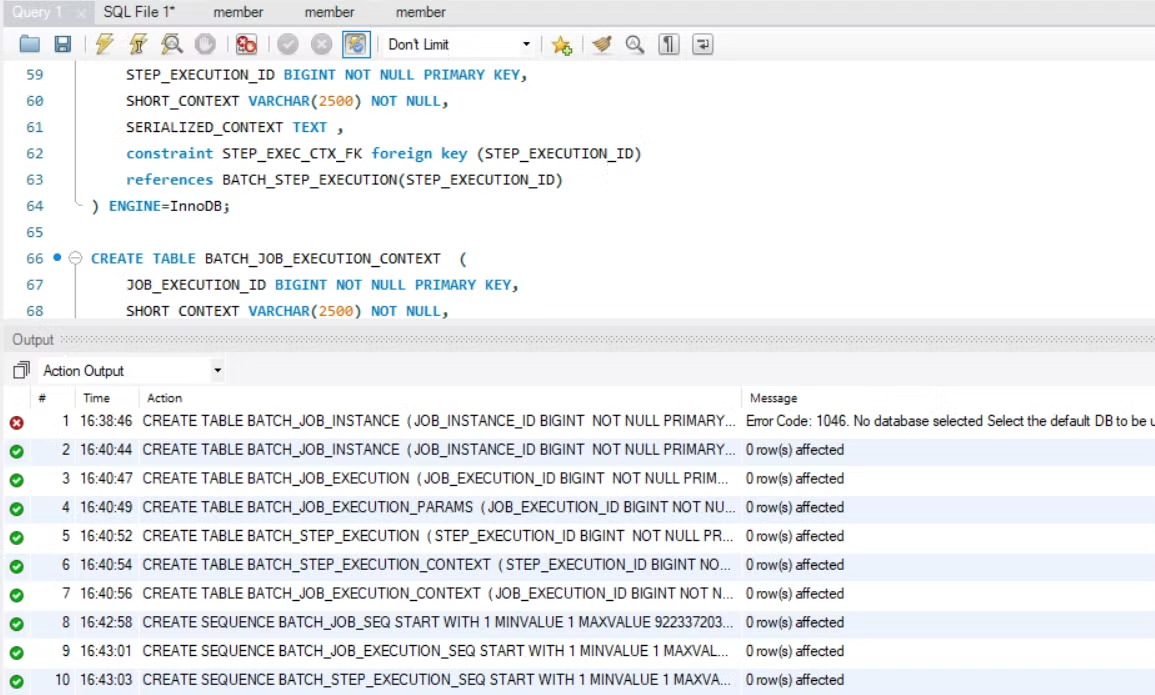
전부 다 추가를 해 주고, 이제 작업을 하면 된다.
테스트를 하기 위해 간단하게 Entity를 만들었다.
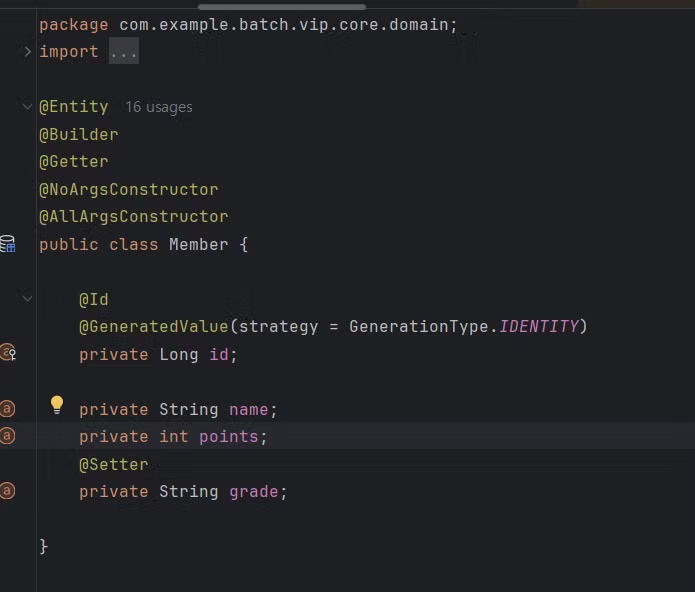
포인트와 이름, 그리고 등급을 가지고 있다.
VipJobConfig 를 설정해서 이 등급들에 대해 배치처리를 해 주면 되는 것인데
- ItemReader : 데이터 소스에서 데이터를 읽어오는 역할
@Bean
public ItemReader<Member> vipReader() {
System.out.println("reader 실행");
return new JpaPagingItemReaderBuilder<Member>()
.name("memberItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("SELECT m FROM Member m WHERE m.points >= 100")
.pageSize(3)
.build();
}JPA를 사용하여 DB에서 member 엔티티를 읽어온다.
entityManagerFactory 를 통해 jpa를 사용하여 테이터를 읽는다.
queryString 으로 jpql 쿼리를 정의하여 point가 100 이상인 member 엔티티를 선택하고, pageSize 는 한 번에 읽을 데이터의 수를 정의하는데 3개로 정의 했다.
- ItemProcessor : 읽어온 데이터를 변환하거나 처리한다.
@Bean
public ItemProcessor<Member, Member> vipProcessor() {
System.out.println("processor 실행");
return member -> {
member.setGrade("VIP");
return member;
};
}Member 객체를 처리하여 등급을 vip로 변경한다. 그리고 변경 된 member 객체를 반환한다.
- ItemWriter
@Bean
public ItemWriter<Member> vipWriter() {
System.out.println("writer 실행");
return new JpaItemWriterBuilder<Member>()
.entityManagerFactory(entityManagerFactory)
.build();
}처리된 데이터를 데이터베이스나 다른 출력 대상으로 기록한다. 여기에서는 jpa를 사용하여 db에 member엔티티를 다시 저장한다.
- Step
@Bean
public Step vipStep(JobRepository jobRepository, PlatformTransactionManager transactionManager, ItemReader<Member> vipReader, ItemProcessor<Member, Member> vipProcessor, ItemWriter<Member> vipWriter) {
return new StepBuilder("testStep", jobRepository)
.<Member, Member>chunk(3, transactionManager)
.reader(vipReader)
.processor(vipProcessor)
.writer(vipWriter)
.transactionManager(transactionManager)
.build();
}step는 배치 작업의 단일 단계로 읽기, 쓰기, 처리 작업을 포함한다.
- StepBuilder 를 사용하여 step를 설정한다.
- chunk(3, transactionManager) 는 청크 단위로 데이터를 처리하고, 한 번에 3개의 Member 객체를 읽고, 처리하고, 쓰기 작업을 수행한다. 트랜잭션은 청크 단위로 관리 된다.
- reader, processor, writer 를 설정하여 데이터의 흐름을 정의한다.
- transactionManager 를 통해 트랜잭션 관리를 설정한다.
- job
@Bean
public Job vipJob(JobRepository jobRepository, Step vipStep) {
return new JobBuilder("vipJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(vipStep)
.build();
}Job은 배치 작업을 정의하는 최상위 객체로, 하나 이상의 step를 포함한다.
JobBuilder 를 사용해서 job을 설정하고, vipJob 작업의 이름을 설정한다.
incrementer(new RunIdIncrementer()) 은 작업 실행시마다 고유한 실행 id를 생성한다.
start(vipStep) 은 작업의 시작 단계를 설정한다.
정리
Reader, Processor, Writer 3개이고
Reader가 읽는 작업을 한다 : db에서 Member 객체를 읽어온다.
Processor가 읽어온 Member 객체의 등급을 vip로 변경하고,
Writer 가 처리된 member 객체를 DB에 저장한다.
이 모든 과정은 step으로 정의 되고, 이 step는 job의 일부로 실행된다.
배치 작업은 job 객체를 통해 실행되며 step 단위로 처리된다.
이제 이렇게 만들어 줬으니, 테스트를 해 봐야한다.
대충 실습 할 값
INSERT INTO member (name, points, grade) VALUES
('Alice', 90, 'A'),
('Bob', 85, 'B'),
('Charlie', 70, 'C'),
('David', 60, 'D'),
('Eve', 110, 'E'),
('Frank', 120, 'F'),
('Grace', 130, 'G'),
('Heidi', 140, 'H');이렇게 값을 넣어주고 실행을 하면
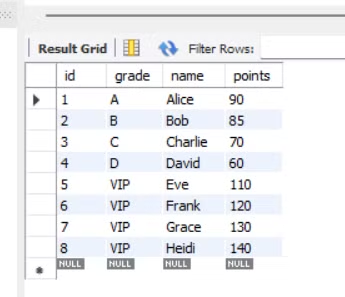
100점 이상인 값의 등급은 vip로 변경이 됨을 볼 수 있다.
여기까지 하겠습니다. 끝 !
안녕하세요 이렇게 또 21주차 회고록이 끝이 났습니다. 이번 주의 간단한,,, 심정을 말 해보자면 시간이 빨리 가는 게 실감 안 나긴 해요. 뭔가 4-5번의 회고록을 더 적으면 이 부트캠프가 끝이 나 정말 사회로 갈 준비를 해야 한다는 것이? 실감이 안 나는 것 같습니다. 지금까지 계속 다른 길을 걸어오다가, 이번 년도에 한화시스템 부트캠프를 들으며 새로운 길을 열게 되었는데 어떻게 될지 아직까지 모르겠습니다 ,, 불안한 마음을 가지고 매일을 살아가는데, 최선을 다 하려고 노력 하는 것 같아요.
IT 취업을 준비하시는 분들, 제 목표인 이미 개발자를 이루신 분들 모두 존경하고 응원합니다,, !
이 부트캠프 내에서 제가 도움 받지 않은 사람 하나 없는 것 같습니다. 모두 너무너무 감사하고 항상 좋은 하루 보내길 바랄게요 ❤
이제 정말 끝 !

'ETC > 한화시스템' 카테고리의 다른 글
| 한화 시스템 부트 캠프 23주차 회고 (5) | 2024.10.06 |
|---|---|
| 한화 시스템 부트 캠프 22주차 회고 (5) | 2024.09.29 |
| 한화 시스템 부트 캠프 20주차 회고 (4) | 2024.09.24 |
| 한화 시스템 부트 캠프 19주차 회고 (6) | 2024.09.08 |
| 한화 시스템 부트 캠프 17주차 회고 (4) | 2024.08.25 |



