
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 엘라스틱서치
- nplus1
- selenium
- kafka배포
- XSS
- 헥사고날아키텍처
- 하이브리드접근법
- 자동화워크플로우
- JPA
- 프로세스와스레드의차이
- 자바
- jwt토큰
- 메소드
- 부트캠프
- springboot
- 스프링시큐리티
- STOMP
- 캐시의 작동 원리
- Java
- 오블완
- 티스토리챌린지
- Kafka
- QA
- 한화시스템부트캠프
- 프로토콜역할
- N+1문제
- n8n
- 자료구조
- 테스트케이스
- 오버로딩
- Today
- Total
아쿠의 개발 일지
한화 시스템 부트 캠프 19주차 회고 본문

안녕하세요 18주차 회고록이 어디 갔는지 궁금 하시다면 다음 주에 오시면 됩니다 !
일단 당장 해온 것을 적고자 하는 마음에 19주차 먼저 적게 되었습니다...
최종 프로젝트를 시작하게 되었고, 전 주에는 데브옵스 토이 프로젝트 최종을 마무리 했습니다!
새로운 팀원들과 함께 최종 프로젝트를 시작 한 만큼 설레는 마음이 더 컸습니다 ,,, 🤍 우리 팀들 사랑(?)해 ,,,
최종 프로젝트를 시작한 만큼 프로젝트 일정 관리를 철저하게 관리하고 있습니다.
일단 팀 구성이 짜졌고, 멘토님을 만나게 됐습니다.
그리고 산출물 계획을 세우게 됐는데, 단계로는
1. 프로젝트 기획
2. 백엔드 설계 및 구축
3. 프론트엔드 설계 및 구축
4. 시스템 통합
5. 프로젝트 발표
이렇게 진행되는 것 같습니다 ,, ! 산출물 구분에 대해서도 강사님이 명확하게 나눠주셨고, 일정 관리를 위해 언제까지 해야 하는지 날짜를 지정 해 주셨습니다. 현재 9월 8일인 지금 백엔드 설계 및 구축에 들어가고 있습니다!
프로젝트 기획서와, 요구사항 정의서, 시스템 아키텍처 설계서, WBS, ERD, 화면 설계서를 모두 마쳤고
조금씩 보여드리자면
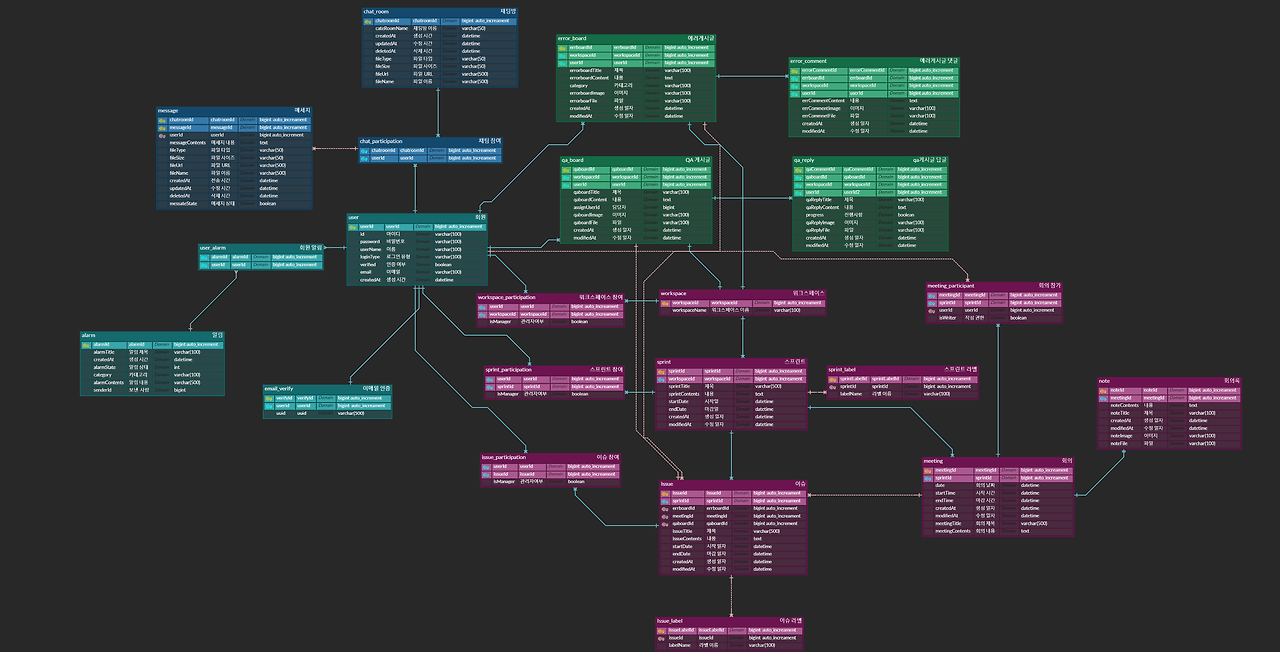

이렇게 구성 했습니다! 저희 팀은 일정 관리 시스템 주제를 맡게 되었고, 그에 맞춰 ERD를 설계 했습니다.
일정 관리하면 생각 나는 게 여러가지 있으실텐데, 저희 팀의 코어 기능은 3가지로 채팅, 캘린더, 게시판으로 정하게 되었습니다.
어떤 결과물이 나올지 궁금하시다면 ,, 열심히 제 블로그 와 주시면 됩니다.
저는 이 3가지 기능 중 채팅을 맡게 되었고, 시스템 아키텍처를 보시면 아시겠지만 kafka를 사용하여 구현 할 예정입니다.
일단 예전 수업을 하면서 Kafka를 배웠던 적이 있었는데요, 스프링 들어가고 11일 때 배웠습니다.
실시간 양방향 통신을 하며, 메세지를 보존할 수 있고, 한 메세지를 여러 구독자에게 전달할 수 있는 Kafka와 STOMP를 활용하기로 했습니다. 두개를 함께 사용하면 그룹 및 개인 채팅에서 실시간성과 확장성을 모두 확보할 수 있으며 대규모 사용자 환경에서도 성능 저하 없이 원활하게 운영할 수 있습니다.
STOMP로 즉각적인 실시간 통신을 처리하고, Kafka로 대용량 메시지 처리 및 안정적인 데이터 전송을 보장하는 구조가 유효합니다.
일단 프로젝트를 진행하기 위해 환경 구성이 필요했고, 구성 방법에 대해서 말씀 드리겠습니다. vmware를 사용했습니다!
최종 배포 전에는 도커를 통해서 재구성 할 예정입니다. (DB를 vmware를 통해 쓰고 있어서 ,, 일단은 여기에 했습니다.)
sudo sed -i -e "s|mirrorlist=|#mirrorlist=|g" /etc/yum.repos.d/CentOS-*
sudo sed -i -e "s|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g" /etc/yum.repos.d/CentOS-*
yum install -y wget
yum install -y java-11-openjdk-devel.x86_64
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz
tar zxvf kafka_2.13-3.7.1.tgz
일단 카프카를 실행하기 위해서는 주키퍼가 실행 되어 있어야 합니다.

Producer, Consumer
발행자(Producer)
메세지를 생산하는 주체
메세지를 만들고 브로커(Broker)에게 토픽(Topic)으로 분류된 메시지를 전달
메시지는 배치 형태로 전달
발행자는 구독자의 존재를 알지 못함
구독자(Consumer)
소비자로 메세지를 소비하는 주체
발행자의 존재를 알지 못함
원하는 토픽을 구독하여 스스로 조절해가면서 소비할 수 있음
원하는 토픽의 각 파티션에 존재하는 오프셋의 위치를 기억하고 관리하여 데이터의 중복을 관리
오프셋 관리를 통해 발행자, 구독자에 장애가 발생해도 마지막으로 읽었던 위치에서 부터 다시 구독 가능
fail-over에 대한 신뢰가 존재
카프카 구성 및 실행 방법
주키퍼 실행
상대경로/bin/zookeeper-server-start.sh 상대경로/config/zookeeper.properties
카프카 실행
vi 상대경로/config/server.properties
38번 라인 수정
advertised.listeners=PLAINTEXT://[카프카 서버로 접속할 수 있는 주소]:9092
125번 라인 수정
zookeeper.connect=[주키퍼 서버 IP주소]:2181
ex ) zookeeper.connect=10.10.10.11:2181
상대경로/bin/kafka-server-start.sh 상대경로/config/server.properties
어떤식으로 실행되는지 참고 해 주시면 됩니다. 주소를 잘 입력 해 주고, 동작하면 됩니다. 이제 백엔드 환경 구성을 보여드릴 건데요
현재 config 구성은

이렇게 해 뒀습니다.
@Configuration
@EnableWebSocketMessageBroker
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/chat")
.setAllowedOriginPatterns("*") // 모든 도메인에서의 CORS 허용
.withSockJS();
}
@Override
public void configureMessageBroker(MessageBrokerRegistry registry) {
registry.enableSimpleBroker("/sub");
registry.setApplicationDestinationPrefixes("/pub");
}
}
import 부분을 빼고 보여드리자면, webSocketConfig는 STOMP랑 WebSocket 설정을 담당하고 있습니다.
`registerStompEndpoints` 여기에서 설정해주는 엔드포인트를 통해서 클라이언트가 WebSocket 연결을 시작하게 되고,
`setAllowedOriginPatterns` 모든 도메인에서 위 엔드포인트로 연결을 허용한다는 뜻입니다.
`SockJS` WebSocket을 지원하지 않아도 접속을 허용 한다는 것입니다.
`configureMessageBroker` ?
`enableSimpleBroker` : 메세지 브로커가 /sub으로 시작하는 구독 경로를 처리한다는 뜻입니다. 이 경로로 오는 구독 요청은 클라이언트에게 전달됩니다.
`setApplicationDestinationPrefixes` : 클라이언트가 서버로 메세지를 보낼 때 사용하는 경로의 접두사입니다.
클라이언트가 /pub 으로 메세지를 보내면 서버에서 이를 처리하고 브로커로 전달합니다.
// 정리 //
클라이언트가 /pub/chat로 채팅을 보내면
서버가 MessageMaping("/chat") 을 찾아서 메소드를 실행한다.
메세지 처리 후 sendTo("/sub/chat") 에 의해 /sub/chat로 전달한다
/sub/chat를 구독하고 있는 모든 클라이언트들이 kafka로 받아온 메세지를 수신한다
kafka:
producer:
bootstrap-servers: ${KAFKA_SERVER}
consumer:
bootstrap-servers: ${KAFKA_SERVER}kafka 서버 주소들을 설정했습니다. 환경 변수로 설정해서 local.yml에서 입력해주면 이를 통해
> @Value("${spring.kafka.producer.bootstrap-servers}") <
위에 있는 곳으로 주소가 들어가게 됩니다.
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String kafkaBroker;
@Bean
public ConsumerFactory<String, String> stringConsumerFactory() {
return new DefaultKafkaConsumerFactory<>(stringConsumerConfig());
}
@Bean
public Map<String, Object> stringConsumerConfig() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBroker);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.GROUP_ID_CONFIG, KafkaConstants.GROUP_ID);
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return config;
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> stringKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(stringConsumerFactory());
return factory;
}
@Bean
public ConsumerFactory<String, MessageRequest> messageRequestConsumerFactory() {
return new DefaultKafkaConsumerFactory<>(messageRequestConsumerConfig());
}
@Bean
public Map<String, Object> messageRequestConsumerConfig() {
Map<String, Object> config = new HashMap<>();
JsonDeserializer<MessageRequest> deserializer = new JsonDeserializer<>(MessageRequest.class);
deserializer.setRemoveTypeHeaders(false);
deserializer.addTrustedPackages("*");
deserializer.setUseTypeMapperForKey(true);
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBroker);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializer);
config.put(ConsumerConfig.GROUP_ID_CONFIG, KafkaConstants.GROUP_ID);
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return config;
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, MessageRequest> messageRequestKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, MessageRequest> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(messageRequestConsumerFactory());
return factory;
}
}
KafkaConsumerConfig는 메세지를 수신하는 것을 담당하고 있습니다.
consumerFactory는 Kafka에서 메세지를 수신하는 consumer를 생성하는 곳이고,
JsonDeserializer는 카프카에서 수신한 메세지를 Java 객체로 변환하는 역할을 합니다.
ConcurrentKafkaListenerContainerFactory는 카프카에서 비동기적으로 메세지를 수신하는 리스너를 생성합니다. factory라는 이름의 리스너 컨테이너 생성합니다.
serConsumerFactory를 통해 어떻게 처리 할 건지 정의하고 나중에 @kafkaLisner라는 어노테이션과 연동해서 메세지를 처리하는 로직을 짜게 됩니다.
현재 위 구현 방법은 <String, String> 형식인 메세지만 받는 형태와, <String, MessageRequest> 라는 제가 설정한 파일까지 받게 하려고 만든 Request이기에 3개씩 있어서 복잡해 보이실 수 있습니다. 자세히 보시면 같은 거 두개 있는,,겁니다,,
package minionz.backend.config.kafka;
import java.util.UUID;
public class KafkaConstants {
// public static final String GROUP_ID = "chat-message-consumer-group";
public static final String GROUP_ID = UUID.randomUUID().toString();
}
받아오는 그룹id는 uuid로 되도록 구성했고, 왜 위에 주석 처리 된게 있는지는 아래에서 설명 해 드리겠습니다 ,,
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String kafkaBroker;
@Bean
public ProducerFactory<String, String> stringProducerFactory() {
return new DefaultKafkaProducerFactory<>(stringProducerConfig());
}
@Bean
public Map<String, Object> stringProducerConfig() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBroker);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return config;
}
@Bean
public KafkaTemplate<String, String> stringKafkaTemplate() {
return new KafkaTemplate<>(stringProducerFactory());
}
@Bean
public ProducerFactory<String, MessageRequest> messageRequestProducerFactory() {
return new DefaultKafkaProducerFactory<>(messageRequestProducerConfig());
}
@Bean
public Map<String, Object> messageRequestProducerConfig() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBroker);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return config;
}
@Bean
public KafkaTemplate<String, MessageRequest> messageRequestKafkaTemplate() {
return new KafkaTemplate<>(messageRequestProducerFactory());
}
}
Kafka ProducerConfig는 DefaultKafkaProducerFactory를 생성해서 Kafka 프로듀서를 구성합니다.
Producer를 구성할 때 필요한 설정을 Map<String, Object> 방식으로 받아서 만듭니다.
이런식으로 kafka 구성을 마치고, 메세지를 보내고, 채팅방을 만들어서 토픽을 저장하는 방식을 구현하고 있었는데
> ConsumerConfig.GROUP_ID_CONFIG 에러
가 계속 뜨게 됐습니다. 분명 위에 uuid로 그룹 아이디를 받아오도록 consumer에서 구성을 해 줬는데도 에러가 뜨길래 찾아 보니
정말 이유를 모르겠습니다 ,, 되어야 하는데 안 되길래 임시 방편으로
1. uuid를 받아오지 말고 하드 코딩 할 것
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroupId");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
위처럼 그룹아이디를 직접 지정 해 주고, KafkaListener에서 아래처럼 지정 해 줬을 때 에러가 사라졌습니다.
@KafkaListener(topics = "example-catalog-topic", groupId = "consumerGroupId")
2. application.yml 에 group_id를 설정해 줄것
안 된다면 위 두개의 방법을 쓰면 되는데, consumerconfig가 제대로 작동을 안 하는 것이니 꼭 고치고 넘어가야 할 것 같아서 위와 같은 방법으로는 해결하지 않기로 했습니다 ,,
consumerconfig에 있는 messageRequestConsumerConfig 부분을 제대로 읽어오지 못 하는 것 같은데요 ,, 이 부분은 다음 주의 제가 해결 해 보도록 하겠습니다.
끝 !
Problem
코어 기능을 정하는 시간에 채팅이 막연하게 두려워서 하기 싫다고 당당하게 말 했다. 하지만 돌아오는 것은 채팅이었다. 어차피 하게 될 것이라면 두려워하지 말기 ,, 쟨 그래도 코드고 난 사람인데 내가 더 강하지 않을까?
무엇이든 시작도 하지 않고 두려워 하는 마음을 고쳐보도록 하자...
주말이라 집에서 코드를 짜게 돼서 강의실에서 브리지 구성으로 한 것을 NAT 구성으로 다 바꾸니 설정에 무슨 문제가 생겼는지 kafka가 제대로 동작하지 않아 테스트를 못 해보았다 ,, 이 점을 다시 살펴보고 추석 때 구현해야 하니까 꼭 알아보자 !
Try
stomp랑 kafka를 완벽하게 이해 해야 채팅 기능을 구현하고, 나중에 발표 할 때도 유연하게 할 수 있을 것이다. 코드만 짜지 말고 어떻게 동작 구성이 되는지 지금처럼 노트에 써가며 공부하면서 짜 보도록 하자. (시간이 없는 거 같기도 ,, )
'ETC > 한화시스템' 카테고리의 다른 글
| 한화 시스템 부트 캠프 21주차 회고 (3) | 2024.09.28 |
|---|---|
| 한화 시스템 부트 캠프 20주차 회고 (4) | 2024.09.24 |
| 한화 시스템 부트 캠프 17주차 회고 (4) | 2024.08.25 |
| 한화 시스템 부트 캠프 16주차 회고 (1) | 2024.08.25 |
| 한화 시스템 부트 캠프 15주차 회고 (1) | 2024.08.25 |



